一、文本的向量表示:从字符到语义空间
在深度学习模型中,文本信息并不是以字符或单词的形式直接使用的,而是通过词嵌入(Word Embedding)将每个词映射到一个高维向量(如 300 维、768 维等)。这种向量编码了词的语义和语法信息。
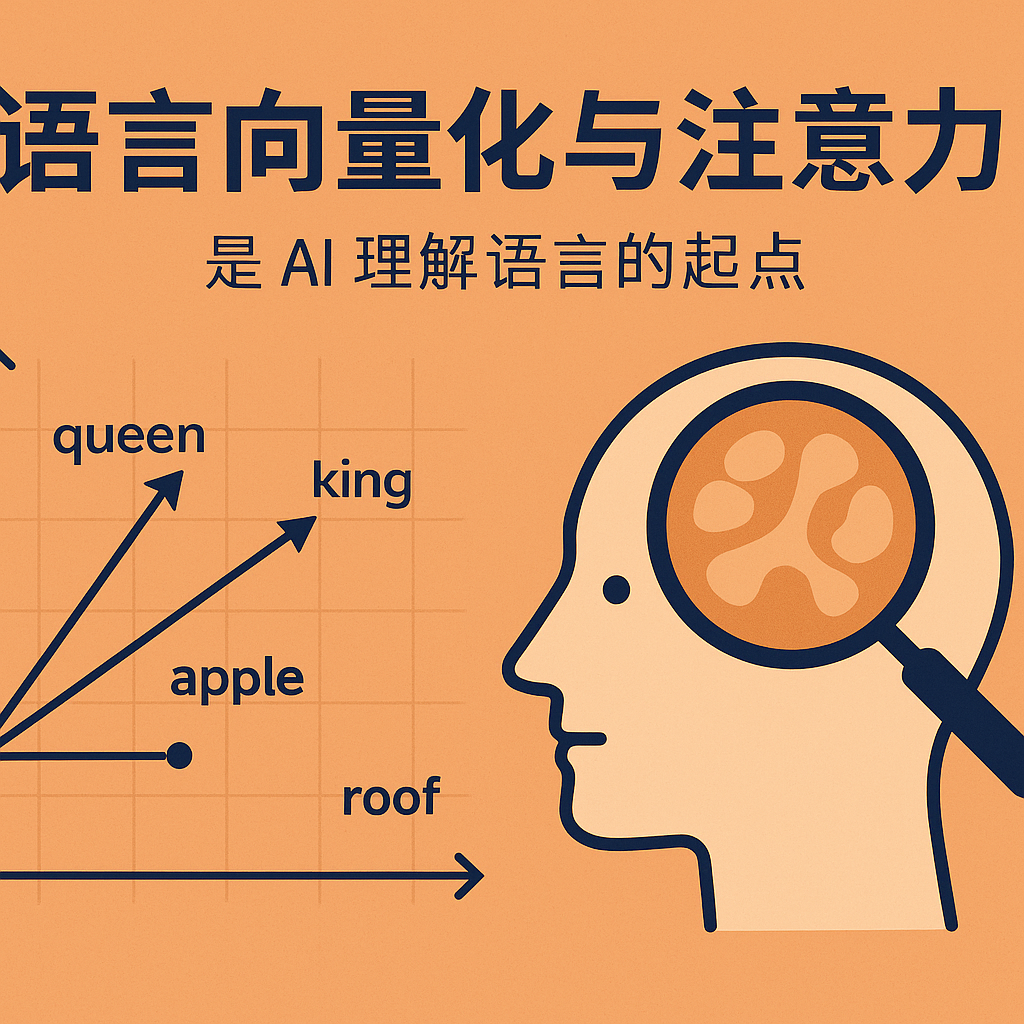
向量化的核心目标是:让语义相近的词具有相近的向量。例如,“king” 和 “queen” 在向量空间中距离较近,而 “apple” 和 “roof” 的距离较远。这使得我们可以用数学方式操作这些向量,比如查找同义词、构建类比等。
二、向量之间的数学关系
向量之间的关系可以从多个数学角度进行描述,包括:
- 几何关系:距离、夹角、投影
- 代数关系:点积、叉积、外积、范数
- 线性代数关系:正交、线性相关、矩阵秩、特征分解
- 概率统计关系:协方差、相关系数
- 拓扑结构关系:归一化、邻域、度量空间
这些关系并不是孤立存在的,它们之间存在内在的联系,我们称之为映射。例如:
- 几何关系可通过点积、范数与矩阵变换来表达;
- 代数运算依赖于矩阵乘法与张量计算;
- 线性相关性可以通过特征分解、行列式等来量化;
- 协方差与相关性可以通过外积与归一化点积来计算;
- 邻域与归一化依赖于范数与空间定义。
这些数学映射形成了一个跨领域的结构,甚至可以被看作某种“同伦类”,也就是说,在本质上具有共同特性,这使我们可以在不同数学表示之间连续地过渡与转化。
常用的方法比如范数归一化、矩阵变换和特征值分解。不同数学领域的关系可以通过某些变换连续地联系在一起。
其中几何关系特别适合用于思考和理解。代数关系适合计算机运算。

三、向量的距离
刚才提到了,文字需要向量化。向量是可以判断距离的。既然相似的单词彼此接近,那么用向量之间的距离来判断它们之间的关系岂不是很合适?
的确,广义上的向量距离有好多种,其中直观的就是欧几里德距离。但是欧式距离并不合适,因为单词的出现频率是很不相同的。频率较高的词(如“the”)可能对应较大的向量。频率较低的词对应较小的向量。由于高频词的向量通常具有较大范数,其在空间中离坐标原点非常远,它们之间的欧式距离可能比两个低频词的距离更大,但这并不意味着它们语义上更不相似。低频词之间即使它们之间的意义截然相反,也有可能因为它们都离原点更近而导致其欧式距离更小。
为了消除向量大小对相似性的影响,我们通常使用余弦相似度作为它们之间的距离度量。这种计算会归一化消除范数因素,相当于仅仅考虑向量之间的夹角。公式就是向量的点积除以它们的范数之积。
这种距离计算带来额外的好处,它比欧式距离更便宜。因为欧式距离定义为每一维坐标差的平方和再开平方根。其它的距离(曼哈顿距离,汉明距离等等)各有各的应用场景,但是余弦相似度计算广泛用于自然语言处理。
四、从 n-gram 到 Seq2Seq:语言建模的演化
这种思路用来处理自然语言,最早的模型就是 n-gram,通过计算一个固定长度窗口内的单词相似性,用来预测接下来的词。这可以产生语法上非常准确,但是语义混乱不合逻辑的文本。虽然语义不合逻辑,但是语法非常准确。说明至少已经捕捉到文本中的一部分底层规则,接下来的挑战就是如何捕捉更多的规则。
但是n-gram窗口难以扩大,因为运算呈指数级上升。因此循环神经网络RNN被借用来一个词一个词的处理文本,RNN历史悠久,主要用于信号处理,没想到用于离散的文字效果也很好。它一个词一个词地处理序列信息,每一步的处理结果都用在下一步里,因此具有一定的上下文记忆能力。LSTM的引入进一步改善了长期依赖问题,同时叠加多层RNN捕捉复杂模式。这些改进,最终发展成Seq2Seq模型,在机器翻译领域取得了非常好的效果。
Seq2Seq模型包含两个关键部件:
编码器(Encoder):读取源语言句子,将信息存入隐藏状态(hidden state)。
解码器(Decoder):从隐藏状态生成目标语言句子。
因为RNN 需要将整个句子的意义压缩进一个隐藏状态,然后再传给解码器。这种方式会导致长句子的信息丢失,因为隐藏状态无法完全保留全部信息。
另一个RNN 的主要问题是信息需要逐步传递,导致难以捕捉长程依赖,并且计算无法并行。
五、注意力机制:突破瓶颈的关键
为了解决这个问题,是否可以直接从输入到输出建立连接?因此,注意力机制被提出,它允许解码器在生成每个输出时,直接关注输入中最相关的信息。
最简单的方法是平均所有输入时间步的隐藏状态,但这会丢失一种关键信息,比如哪些词更重要?因此,我们使用加权平均,其中权重由 Query(查询)- Key(键)的相似度计算,并通过 Softmax 归一化得到。
最终,我们将注意力加权输出与解码器的隐藏状态拼接,并通过一个线性变换,使模型能够更智能地结合两者的信息,从而提升翻译或文本生成的质量。
六、注意力机制为何有效?它模拟了信息检索
本质上,注意力机制是一种可微分的“键-值查询”操作,它模拟了一个智能的信息检索系统。由于整个机制是连续、可导的,因此可以通过梯度下降优化整个模型。
注意力机制非常符合人类翻译时的直觉:我们在翻译一个词时,并不是回忆整句话,而是快速地扫视上下文,重点关注那些关键的、相关的词。
因此,注意力机制不仅提高了模型的性能,也使得模型具有一定的可解释性。
七、总结:语言向量化与注意力,是 AI 理解语言的起点
从词嵌入到向量之间的数学关系,从简单的 n-gram 到复杂的 Seq2Seq,再到引入注意力机制,深度学习模型正是通过不断优化信息表示与信息检索方式,来逐步提升语言理解与生成的能力。
这些技术不仅是机器翻译的基石,也是现代语言模型(如 Transformer 和 ChatGPT)得以成立的理论支柱。