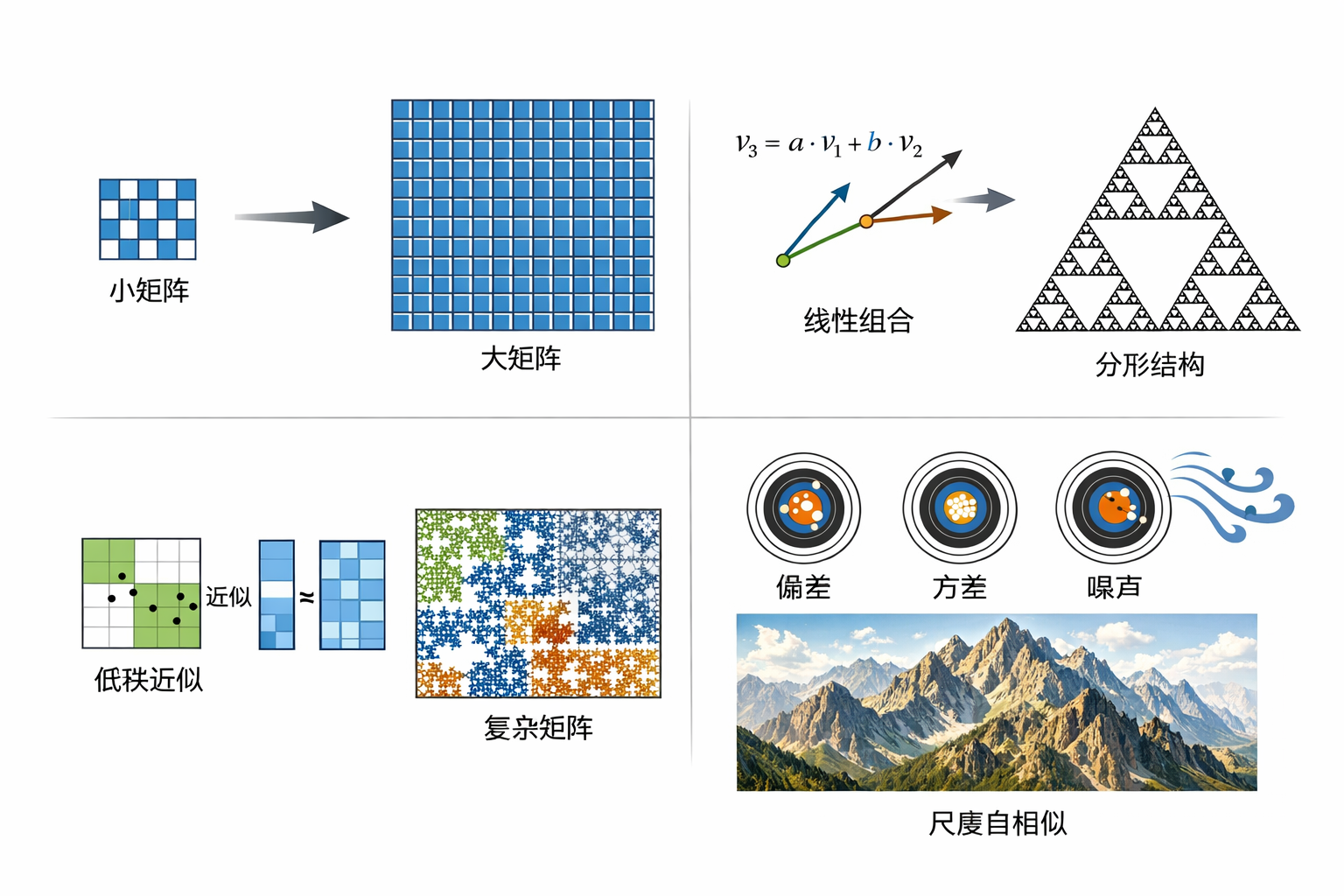
有时候我会把“世界变复杂”的过程,想象成一个矩阵在长大。
一开始只是一个很小的矩阵,行不多,列也不多。后来数据越来越多,行在增加,列也在增加。你也可以换个角度想,不只是二维的扩展,而是维度在不断长出来。
但这里有一个关键问题:新增的数据,到底是“新信息”,还是“旧信息的变形”?
如果只是线性组合——也就是新数据可以用旧数据加权拼出来——那从线性代数的角度,这个矩阵的秩并没有变。你看起来有了更多数据,本质上却没有获得更多自由度。
但现实世界很少这么“规矩”。
更多时候,数据的增长不是线性的,而是某种更微妙的展开方式。比如分形。
自然界的很多结构——树叶、山脉、云、海岸线——都有一个共同特点:你放大看,还是那个样子。尺度变了,规则没变。这种自相似性,本质上来自于基本作用机制在不同尺度上的一致性。
如果把这种机制搬到数据上,你会得到一种很有意思的结构:整体看起来非常复杂,但它其实是由少量规则不断递归展开出来的。
换句话说,它是低维信息,通过非线性的方式“长出来”的。
这种情况下,就会出现一个很反直觉的现象:
一个看起来维度很高、秩很高的矩阵,其实可以被一个很低秩的结构很好地近似。
原因很简单——信息是冗余的,而且这种冗余是有结构的。
自相似带来的,不只是重复,而是“有偏好的重复”。某些方向的信息被不断强化,而另外一些方向几乎是空的。这种分布的不均匀性,使得奇异值谱往往呈现长尾:前面几维承载了大部分信息,后面的维度虽然存在,但贡献极小。
这也是为什么很多高维数据,用低秩近似效果 surprisingly 好。
但如果你还停留在“线性秩”的框架里,这一切其实是解释不通的。
线性代数默认了一件事:信息是通过线性组合扩展的,向量之间的关系是线性的,高维结构是在一个线性空间里铺开的。
问题是,现实数据往往不是这样构造的。
图像、语言、行为轨迹、金融时间序列——它们更像是分布在某个低维的非线性流形上,而不是一个均匀的高维空间。
局部来看,每一小块结构都很简单,甚至有点重复;但整体拼起来,却异常复杂。这种“局部简单 + 全局复杂”的组合,本质上就是分形思维在起作用。
所以,与其问“这个矩阵的 rank 是多少”,不如换个问题:
它背后的“本质维度”是多少?
这个维度,未必是线性的。它可能是一个流形的维度,也可能是一个分形维度。
前者描述的是:数据点实际上贴在一个弯曲的低维空间上。
后者描述的是:这个结构在不同尺度上的复杂度如何增长。
一旦你从这个角度看问题,很多技术路径就自然出现了。
比如 t-SNE、UMAP 这些非线性降维方法,本质上是在试图还原那个低维流形的结构;小波变换、金字塔模型是在做多尺度分解;而神经网络,尤其是自监督学习,本质上是在学习一种“低维但复杂”的表示分布。
换句话说,我们正在用一整套“超越线性代数”的工具,去逼近真实世界的数据结构。
但建模这件事,从来都不只是“选一个更高级的方法”这么简单。
只要你开始建模,就会遇到三个老问题:偏差、方差和噪声。
如果模型选错了,比如你用线性模型去拟合一个本质上是分形结构的数据,那你的偏差会很大。就像一把精度不够的枪,瞄准本身就是错的。
如果模型太复杂,又没有足够的数据约束,它就会过拟合。你会得到一个在训练数据上几乎完美,但一换数据就崩掉的模型。这更像是手在抖,每一枪都不稳定。
而噪声,是你无论如何都绕不过去的东西。它像风。你再精准、再稳定,也总有不可控的扰动。
有意思的是,当数据本身具有分形结构时,这三者之间的关系会变得更加微妙。
分形意味着“模式在重复”,但这种重复不是完全一致,而是带着扰动的。这种扰动,一部分是结构性的(你可以建模),一部分是随机的(你只能接受)。
如果你把结构性的部分当成噪声丢掉,你会提高偏差;如果你把随机噪声当成结构去拟合,你会提高方差。
真正困难的,不是拟合数据,而是分辨:哪些复杂性是“应该被解释的”,哪些只是“世界本来就会抖动”。
回到最开始那个矩阵的比喻。
它确实在变大。但更重要的不是它有多少行、多少列,而是它是“怎么长出来的”。
如果你看懂了这个“生长机制”,你就不会再执着于 rank 这种单一指标,而会去寻找更接近本质的描述方式。
那时候,你看的就不再是一个矩阵,而是一个正在展开的世界。